The Question I Keep Asking Local Models
I have been running local models on my own device using LM Studio, and the main question in my head is simple:
What task can small local models do reliably?
Not impressively once.
Not with the perfect prompt.
Not in a demo where everything is already arranged to make the model look good.
Reliably.
That is the word I keep coming back to.
I have tried local models for question answering, minor coding, agentic file editing, and plan mode. Some of them could answer simple prompts well enough. Some could explain concepts decently. Some could write small code snippets that looked reasonable at first glance.
Then I tried to make them behave like full coding agents.
That is where things started falling apart.
The models would lose track of files, misunderstand instructions, overconfidently edit the wrong thing, or produce plans that looked structured but did not survive contact with an actual repository. It was not a small failure. It was the kind of failure that reminds you why frontier models like ChatGPT, Claude, and Gemini still feel different once the task becomes multi-step, contextual, and messy.
But I do not think that makes local models useless.
It just means the right question is not:
Can this replace a frontier model?
The better question is:
Where is this small model good enough that I can trust it?
My Current Local Model Shelf
Right now, my local model experiments are a bit of a small model tasting menu. Some are coding-focused, some are general instruction models, and some are specialized.
Model | Parameters | Publisher | Base / Repo | Quant | Size |
|---|---|---|---|---|---|
Qwen 3 MoE | 30B-A3B | lmstudio-community |
|
| 14.6 GB |
Qwen2.5 Coder | 14B | lmstudio-community |
|
| 15.7 GB |
DeepSeek R1 Qwen | 8B | lmstudio-community |
|
| 6.7 GB |
Qwen3.5 | 9B | lmstudio-community |
|
| 8.3 GB |
Gemma 4 | 26B-A4B | unsloth |
|
| 11.3 GB |
Gemma 4 | 12B | lmstudio-community |
|
| 7.6 GB |
There is something exciting about seeing this list on a personal machine.
Years ago, running multiple language models locally felt like something reserved for labs, companies, or people with intimidating GPU setups. Now, I can download models, compare them, run them offline, and ask: what can this actually do for me?
That freedom is fun.
It is also humbling.
Because once the novelty fades, the real work begins: testing where the model is actually reliable.
The Filipino Model That Caught My Attention
The most interesting model I tried recently was not the biggest one on the list.
It was a local model trained by Christopher Dio Chavez, focused on the Philippine Data Privacy Act of 2012, or RA 10173.
I was fortunate enough to meet him at Python Asia 2026 during his talk, "Weaponizing Python for Good: Building a Next-Gen CVE Scanner That Detects Zero-Day Vulnerability." I wrote about that event in my Python Asia 2026 post, and one thing that stayed with me from that whole experience was the energy around open source and local builders.


So when I saw that he released an AI assistant for Philippine data privacy law, I had to try it.
The Ollama model page describes it as "The First Filipino specialized Philippine Data Privacy Law AI Assistant Model" and provides a local command:
ollama run chrisdiochavez/RA10173-DPA2012-AI-ASSISTANTThe stated goal is promising: an offline, air-gapped assistant that can help interpret RA 10173, explain National Privacy Commission guidance, support breach response workflows, and provide structured legal reasoning for privacy decisions.

That matters.
Not because it suddenly replaces lawyers, Data Protection Officers, or compliance teams. It does not, and the model's own disclaimer says it should not be treated that way.
It matters because someone is attempting to build a Filipino legal-domain model around a real Philippine law.
That is a step forward.
What I Tested
I tried the model through LM Studio and asked questions around RA 10173, including:
- What is RA 10173?
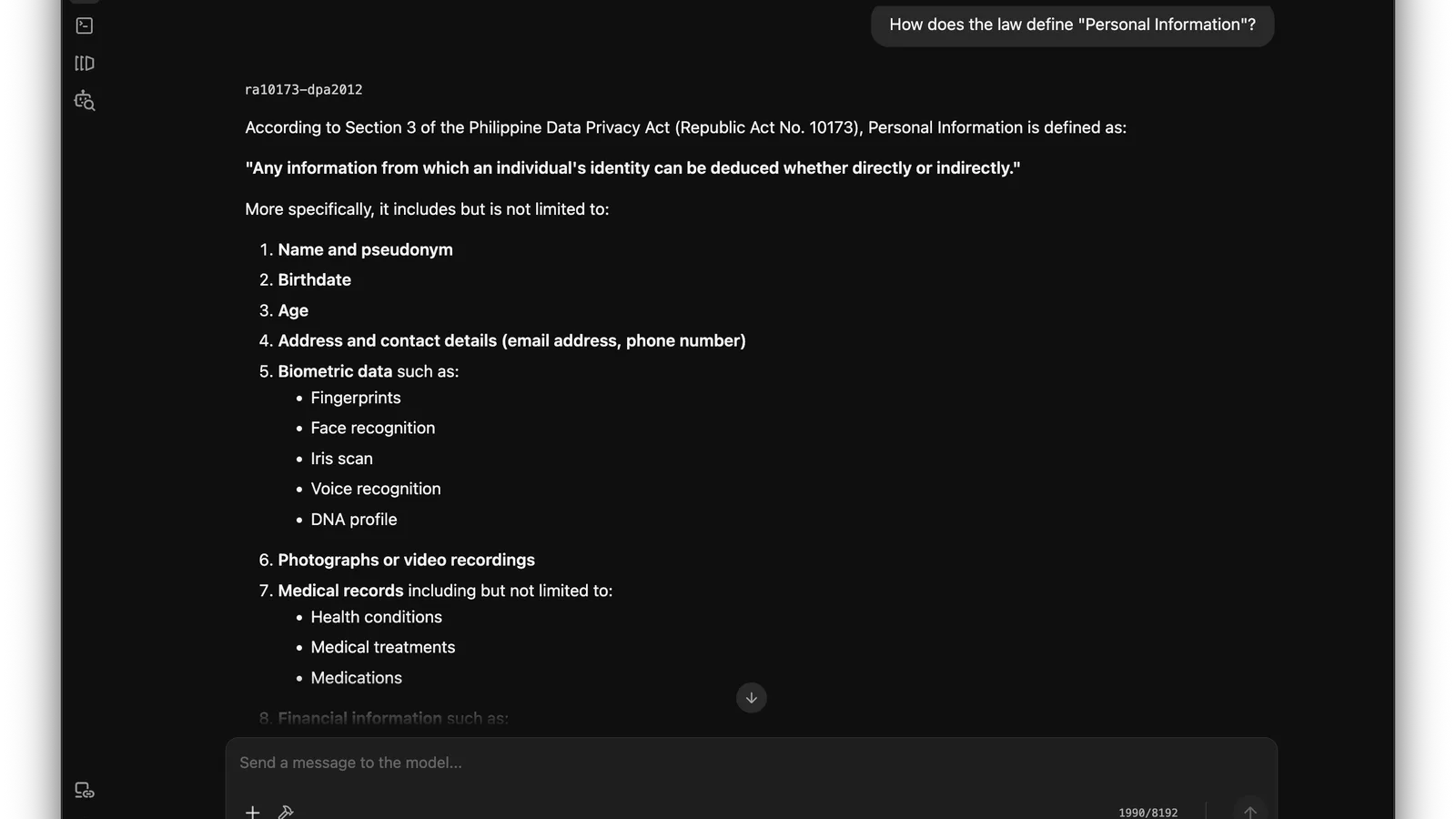
- How does the law define "Personal Information"?
- What is the exact difference between "Personal Information" and "Sensitive Personal Information"?
- Under what specific three conditions is mandatory Data Breach Notification triggered?
- What are the exceptions where RA 10173 does not apply?
The model itself is small by frontier standards:
- Architecture: Llama
- Parameters: 8B
- Context length: 128K
- Quantization:
Q4_K_M - Size: around 4.9 GB
- Temperature: 0.2
That setup is already impressive from a local deployment perspective. A 4.9 GB model that can run offline and answer Philippine data privacy questions is not trivial.

But the actual outputs showed the hard part of building legal AI:
Legal assistants do not only need to sound correct. They need to be anchored to the exact law.
Where It Worked
The model did understand the general topic.
It knew that RA 10173 refers to the Philippine Data Privacy Act of 2012. It knew the conversation should involve personal information, consent, security measures, data subject rights, breach response, and compliance. It also kept a serious, compliance-oriented tone.
For a casual learner trying to understand the broad shape of data privacy, that is already useful.
A student or early-career developer could ask:
- What is this law generally about?
- Why does personal data matter?
- What kinds of questions should I research next?
- What terms should I look up in the actual statute?
For that kind of exploratory use, I can see the value.
The problem starts when the user asks for exact legal definitions, timelines, and exceptions.
That is where "roughly right" becomes dangerous.
Where It Failed
The biggest issue was what I would call GDPR bleed-through.
The model sometimes mixed RA 10173 with concepts and phrasing that sounded closer to GDPR, OECD privacy principles, or general global privacy law. For example, it gave principles like fairness, purpose specification, minimization, accuracy, and retention limitation. Those are familiar privacy concepts, but RA 10173 specifically names the principles of transparency, legitimate purpose, and proportionality. See it at Section 11.

It also used terms like Data Controller and Data Processor. Those are understandable globally, but the Philippine statutory terms are Personal Information Controller and Personal Information Processor. Defined at Section 1.
That may sound minor, but in legal and compliance work, exact terminology matters.
The model also produced definitions that sounded confident but were not exact statutory wording. For "Personal Information," it generated a paraphrased quote instead of the precise legal text. For "Sensitive Personal Information," it listed items that do not belong in the statutory definition, including examples like police blotters, seals and signatures, and vehicle plate numbers.
The most serious failures appeared in operational compliance answers.
For data breach notification, the model answered with a 24-hour notification timeline to the National Privacy Commission and 30 days for data subjects. My analysis flagged this as incorrect against the actual Philippine breach notification framework, where the expected timeline is 72 hours upon knowledge of, or reasonable belief of, a breach for both the NPC and affected data subjects when the notification conditions are met.

It also described breach triggers too broadly, instead of grounding the answer in the specific conditions required by Philippine data privacy rules.
Then came the exceptions question.
The model suggested that areas like BPO and medical records were exempt. That is a major red flag. BPOs are not simply exempt from RA 10173. Medical records are not casually outside privacy regulation either. In many cases, they are among the very examples where careful handling of sensitive personal information matters.

That is the uncomfortable lesson:
The model was confident enough to be useful-looking, but not reliable enough for actual legal reliance.
Why I Am Still Positive About It
I do not want this post to sound like a takedown.
It is not.
If anything, testing this model made me more interested in local AI, not less.
The failure mode is real, but it is also understandable. A small 8B model, especially one compressed through quantization, will struggle with exact statutory recall. Legal text is unforgiving. One wrong timeline, one invented exception, or one imprecise definition can change the meaning of the advice.
This is where I think the better architecture is probably not "just fine-tune harder."
For a task like RA 10173 assistance, I would trust a small local model much more if it were paired with retrieval-augmented generation, or RAG.
Instead of asking the model to remember the exact law from its weights, the system could retrieve the relevant sections from:
- RA 10173
- Its Implementing Rules and Regulations
- NPC circulars
- NPC advisory opinions
- Official breach notification guidance
Then the model's job becomes narrower:
- Retrieve the right source.
- Quote or cite the relevant section.
- Explain it plainly.
- Say when the retrieved source does not answer the question.
That feels like a much better task for a local model.
Not "be a lawyer in a 4.9 GB file."
More like:
Help me understand the exact source in front of us.
That is smaller.
And smaller is not bad.
Smaller might be the path to reliability.
My Current Theory About Small Local Models
After trying these models, my current theory is this:
Small local models become useful when the task is bounded, checkable, and forgiving.
They are risky when the task requires:
- Exact legal or medical recall
- Multi-file autonomous edits
- Long-horizon planning
- High-stakes decisions
- Strong resistance to hallucination
But they can still be useful when the job is:
- Summarizing a known document
- Classifying notes
- Rewriting drafts
- Generating first-pass questions
- Explaining retrieved text
- Running offline brainstorming
- Helping with low-risk local workflows
That is why I am still experimenting.
I do not need every local model to become a full agent. I do not need an 8B model to compete with frontier systems on every task. I just need to find the small pieces of work where it can be dependable.
Even if the task is tiny, that still matters.
Because a tiny reliable task is more valuable than a huge unreliable promise.
Why This Matters For Filipino Builders
The part that makes me hopeful is not that the RA 10173 model is already perfect.
It is not.
The hopeful part is that Filipino builders are starting to train and release models for Filipino contexts.
That matters because local context is often missing from mainstream AI systems. Philippine law, local compliance workflows, regional language patterns, government processes, and domain-specific realities do not always receive the same attention as US or EU contexts.
So even when a first attempt has problems, it still creates momentum.
It gives people something to test.
Something to critique.
Something to improve.
Something to build on.
That is how open technical communities grow. Someone releases a thing. Other people try it. Some parts work. Some parts break. People document the gaps. The next version gets better.
I hope that is what happens here.
The Ending I Keep Coming Back To
Running local models has made AI feel closer to my desk again.
Not as a cloud API.
Not as a product page.
Not as a benchmark screenshot.
But as something I can download, run, question, break, inspect, and maybe slowly understand.
The RA 10173 assistant is not ready for serious legal reliance based on my small test. It hallucinated important details, and that matters. But I still respect the direction. A Filipino builder tried to make a Filipino legal-domain model that can run locally and offline.
That is worth paying attention to.
My end goal remains the same: I want to find tasks where these small models can be reliable, no matter how small those tasks may be.
And honestly, I am enthusiastic.
I am hopeful.
I hope this momentum continues in the Philippines.
Because maybe the next step for local AI here is not immediately competing with frontier LLMs.
Maybe the next step is simpler:
Build small, useful, Filipino-context AI systems that people can actually trust.